XGBoost¶
学习目标¶
- 知道XGBoost原理
- 了解XGBoost API的常用参数
1. XGBoost 原理¶
XGBoost 是(eXtreme Gradient Boosting)的简称,是优化的分布式梯度提升库:
- 基本原理与GBDT相同,属于Gradient Boosting 类型的机器学习算法,是对GBDT的优化
- 在训练每一棵树的时候GBDT采用了并行的方式进行训练,提高了模型训练速度
- 对比GBDT,XGBoost无论实在训练速度上还是预测精度上都有显著提升
XGBoost属于参数学习算法,最终我们要找到一个函数来表示XGBoost模型,按照下面的思路我们来分析一下XGBoost的原理:
构造目标函数 → 目标函数的优化方法 → 用函数来表示一棵树 → 如何构建树模型
1.1 构造目标函数¶
通过前面章节的学习, 我们介绍了参数学习算法的基本套路:通过优化目标函数来确定参数,比如
- 线性回归、逻辑回归, 我们可以通过梯度下降法来优化目标函数从而得到模型参数
但XGBoost 属于Boosting类集成学习模型, 要串行的训练多个模型逐步逼近降低损失,我们很难找到一个函数通过梯度下降的套路来解决这个问题。
XGBoost 使用多棵树来预测最终的结果,假设已经训练了t棵树,那么对于第i个样本的最终预测值为:
\(\large\hat{y}_i = \sum_{t=1}^{t}f_t(t_i) , f_t\in F\)
上面式子中, \(f_t(x_i)\) 为 第i 个样本 \(x_i\) 在第t棵树上的预测结果
如: \(f_1(x_1)\) 为 第1 个样本 \(x_1\) 在第1棵树上的预测结果
\(f_2(x_1)\) 为 第1 个样本 \(x_1\) 在第2棵树上的预测结果
……
第1个样本的最终预测结果 \(\hat{y_1} = f_1(x_1)+f_2(x_1)+……+f_t(x_1)\)
目标函数可以由下面式子表示:
\(\large Obj=\sum_{i=1}^n l(y_i,\hat{y}_i) + \sum_{t=1}^{t}\Omega (f_t)\)
上式中,左边求和项为损失函数(loss),其中 \(y_i\) 为真实值, \(\hat{y}_i\)为预测值
右边求和项用于控制模型复杂度(penlty 比如线性回归中的L1、L2正则)
XGBoost 的训练过程是一棵树接一棵树的串行训练,在训练第t棵树时,前t-1棵树已经训练结束,可视为已知,在处理目标函数时,重点关注第t棵树的情况:
\(\large \hat{y}_i = \hat{y}_i^{t-1}+f_t(x_i)\)
上式中,\(\hat{y}_i^{t-1}\) 为前t-1棵树的预测值
所以上面的目标函数可以改写成:
\(\large Obj=\sum_{i=1}^n l(y_i,\hat{y}_i^{(t-1)}+f_t(x_i)) + \sum_{t=1}^{t-1}\Omega (f_t)+\Omega(f_t)\)
上式中,\(\sum_{t=1}^{t-1}\Omega (f_t)\) 可以看做是常数(训练第t棵树时,前面t-1棵树都训练完毕),可以忽略,所以目标函数简化为:
\(\large Obj=\sum_{i=1}^n l(y_i,\hat{y}_i^{(t-1)}+f_t(x_i))+\Omega(f_t)\)
1.2 使用泰勒级数展开目标函数¶
直接对目标函数求解比较困难,通过泰勒展开将目标函数换一种近似的表示方式
泰勒级数,是把一个函数展开来显示的无穷级数,可以用泰勒级数的头几项来估计函数的近似值
如果 \(f(x)\) 在点 \(x=x_0\) 具有任意阶导数,则幂级数
\(\sum_{n=0}^∞\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n=f(x_0)+f'(x_0)(x-x_0)+\frac{f''(x_0)}{2!}(x-x_0)^2+...+\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n+...\)
称为 \(f(x)\) 在点 \(x_0\) 处的泰勒级数
这里我们把目标函数进行二阶泰勒级数展开:
\(\large f(x+\Delta x) \approx f(x)+f'(x)\Delta x + \frac{1}{2}f''(x)\Delta x^2\)
我们把目标函数带入上面的泰勒级数:
\(f(x)→l(y_i,\hat{y}_i^{(t-1)}) ,f(x+\Delta x)→l(y_i,\hat{y}_i^{t-1}+f_t(x_i))\)
得到用二阶泰勒级数展开的目标函数
\(Obj=\sum_{i=1}^n [l(y_i,\hat{y}_i^{(t-1)})+∂_{\hat{y}_i^{(t-1)}}l(y_i,\hat{y}_i^{(t-1)})f_t(x_i)+\frac{1}{2}∂^2_{\hat{y}^{(t-1)}_i}l(y_i,\hat{y}_i^{(t-1)})f_t^2(x_i)]+\Omega(f_t)\)
用 \(g_i\) 和 \(h_i\) 来表示上面式子中一阶导数 和 二阶导数的部分, 目标函数整理为:
\(\large Obj\approx\sum_{i=1}^n [l(y_i,\hat{y}_i^{(t-1)})+g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+\Omega(f_t)\)
\(g_i=∂_{\hat{y}_i^{(t-1)}}l(y_i,\hat{y}_i^{(t-1)})\)
\(h_i = ∂^2_{\hat{y}^{(t-1)}_i}l(y_i,\hat{y}_i^{(t-1)})\)
上面的目标函数中,\(l(y_i,\hat{y}_i^{(t-1)})\) 为前t棵树的损失, 可以视为常数项将其忽略, 我们的目标函数可以近似的表示为:
\(\large Obj\approx\sum_{i=1}^n [g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+\Omega(f_t)\)
上面的式子中,\(g_i\) 和 \(h_i\) 是已知的
1.3 把树结构引入到目标函数¶
通过二阶泰勒级数展开, 我们得到了近似的目标函数:
\(\large Obj\approx\sum_{i=1}^n [g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+\Omega(f_t)\)
接下来我们需要用具体的函数来替换上面公式中的 \(f_t(x_i)\) 和 \(\Omega(f_t)\),首先看第t棵树的函数表示\(f_t(x_i)\) :
\(\large f_t(x_i) = w_{q(x_i)}\)
上面式子表示的是第i个样本在第t棵树上的取值, \(q(x_i)\) 表示第 \(x_i\) 个样本在第t棵树中落到的叶子节点编号,如下图中:
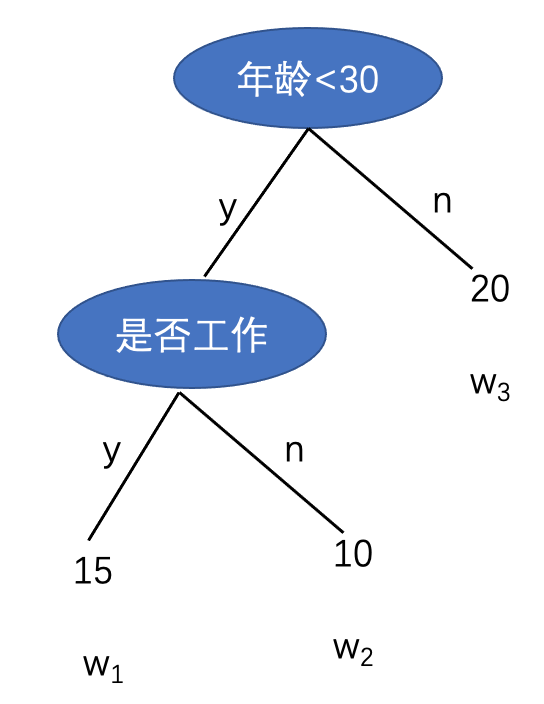
一共有三个叶子节点, 所以 \(q(x_i)\) 的取值可能为:1,2,3 ,那么如果第 \(x_i\) 个样本在第t棵树上落到了第3个叶子节点上, \(q(x_i)\) = 3 此时 \(f_t(x_i) = w_3 = 20\)
后面一项,模型复杂度\(\Omega(f_t)\):
\(\large \Omega(f_t) = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^{T}w_j^2\)
上式中 T 代表叶子节点的个数, γ为一个超参数
对于上面图中的树结构 \(\Omega = \gamma3+\frac{1}{2}(15^2+10^2+20^2)\)
我们把书结构用函数表示后,目标函数为:
\(\large Obj\approx\sum_{i=1}^n [g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+\Omega(f_t)\)
\(\large =\sum_{i=1}^n [g_iw_{q(x_i)}+\frac{1}{2}h_iw_{q(x_i)}^2]+\gamma T+\frac{1}{2}\lambda \sum_{j=1}^{T}w_j^2\)
\(\large =\sum_{j=1}^T [(\sum_{i\in I_j}g_i)w_j+\frac{1}{2}(\sum_{i\in I_j}h_i+\lambda)w_{j}^2]+\gamma T\)
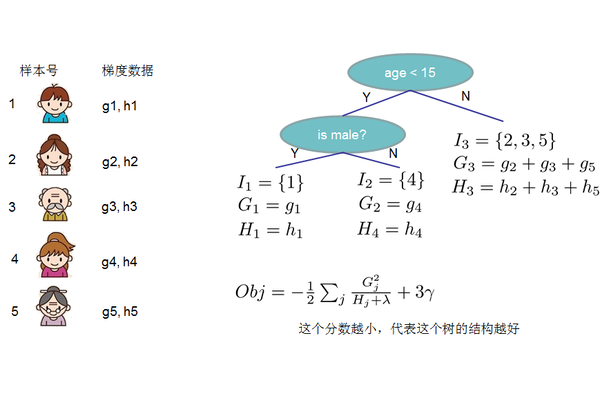
上面式子中 \(I\) 被定义为每个叶子上面样本集合 \(I_j=i|q(x_i)=j\)
如 上图所示的树形结果, 假设:
- 样本1,4,5落到第一个叶子节点
- 样本3落到第二个叶子节点
- 样本2,6落在第三个叶子节点
\(\sum_{i=1}^n g_iw_{q(x_i)}=(g_1w_1+g_4w_1+g_5w_1) +g_3w_2 +(g_2w_3+g_6w_3)=(g_1+g_4+g5)w_1+g_3w_2+(g_2+g_6)w_3\)
\(=(\sum_{i\in I_j}g_i)w_j\)
此时我们进一步令 \(G_j = \sum_{i\in I_j}g_i\) , \(H_j = \sum_{i\in I_j}h_i\) 目标函数可以改写为:
\(\large obj \approx \sum_{j=1}^T [(\sum_{i\in I_j}g_i)w_j+\frac{1}{2}(\sum_{i\in I_j}h_i+\lambda)w_{j}^2]+\gamma T\)
\(\large = \sum_{j=1}^T [G_jw_j+\frac{1}{2}(H_j+\lambda)w_{j}^2]+\gamma T\)
假设我们已经知道树的结构 \(q\),我们可以通过这个目标函数来求解出最好的 \(w\) ,以及最好的 \(w\) 对应的目标函数最大的增益。上面的式子其实是关于 \(w\) 的一个一元二次函数的最小值的问题 ,求解既得到
\(\large w_j^* = - \frac{G_j}{H_j+\lambda}\)
\(\large Obj = -\frac{1}{2}\sum_{j=1}^T \frac{G_j^2}{H_j+\lambda} + \gamma T\)
Obj表示在某个确定的树结构下的结构分数(structure score),这个分数可以被看做决策树中的基尼系数、信息增益(一般决策树评分函数)
1.4 如何构建树¶
由于最终的目标函数:
\(\large Obj = -\frac{1}{2}\sum_{j=1}^T \frac{G_j^2}{H_j+\lambda} + \gamma T\)
是基于我们已经知道了所有树结构的前提,所以暴力的解法是枚举出所有可能的树结构,用上面的函数来进行打分,找到分数最小的,把对应的那棵树加入到模型中, 再不断重复, 但这种暴力解法的时间复杂度过高。
我们可以选择使用一般决策树的构建思路, 采用贪心算法的思路, 对当前树中的每一个叶子节点,用不同特征尝试进行分割,并用下面的函数计算分裂前和分裂后的增益分数,找到最优的分割方案:
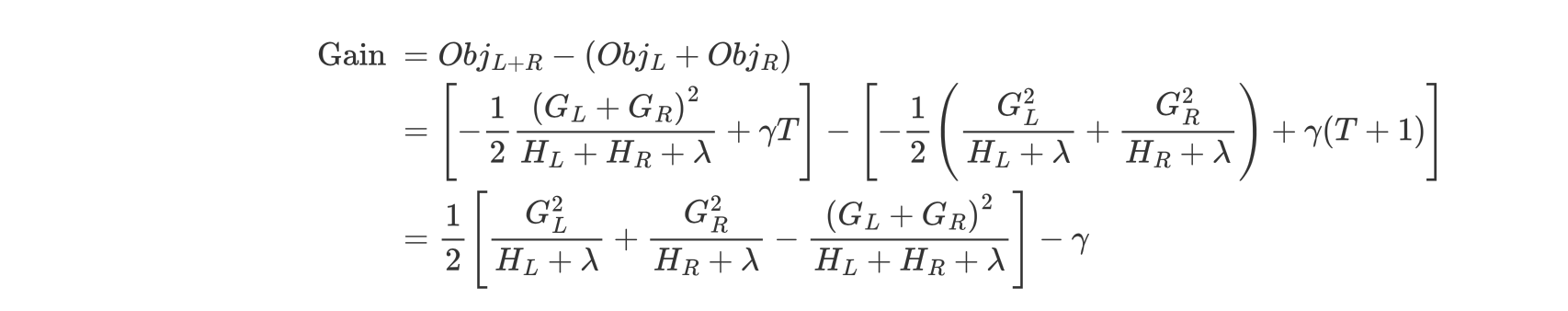
其过程如下:
- 对树中的每个叶子结点尝试进行分裂
- 计算分裂前 - 分裂后的分数:
- 如果分数 > 0,则分裂之后分树的结构损失更小,我们会考虑此次分裂
- 如果分数 < 0,说明分裂后的分数比分裂前的分数大,此时不建议分裂
- 当触发以下条件时停止分裂:
- 达到最大深度
- 叶子结点样本数量低于某个阈值
- 等等...
1.5 XGBoost缺失值处理¶
实际的项目中的数据一般会存在缺失数据,因此在寻找最佳分割点时需要考虑如何处理缺失的特征,作者在论文中提出下面的算法

对于特征k,在寻找split point时只对特征值为非缺失(non-missing)的样本上对应的特征值进行遍历,统计量G和H则是全部数据上的统计量。
在遍历非缺失(non-missing)的样本 \(I_k\)时会进行两次:
-
按照特征值升序排列遍历时实际是将missing value划分到右叶子节点
-
按照特征值降序遍历则是划分到左叶子节点
最后选择score最大的split point以及对应的方向作为缺失值的划分方向.
在预测阶段,如果特征\(f_0\)出现了缺失值,则可以分为以下两种情况:
如果训练过程中,\(f_0\)出现过缺失值,则按照训练过程中缺失值划分的方向(左或右),进行划分;
如果训练过程中,\(f_0\)没有出现过缺失值,将缺失值的划分到默认方向(左子树)。
1.6 XGBoost原理小结¶
-
构造目标函数 ,XGBoost是一棵树一棵树训练模型, 所以目标函数可以表示为前t-1棵树的损失+第t棵树的损失+控制模型复杂度的惩罚项 \(Obj=\sum_{i=1}^n l(y_i,\hat{y}_i^{(t-1)}+f_t(x_i))+\Omega(f_t)\)
-
使用二阶泰勒泰勒级数展开目标函数: 直接求解目标函数比较困难,使用二阶泰勒级数展开目标函数。将结果整理后, 目标函数可以表示成 第t颗树的函数 \(Obj\approx\sum_{i=1}^n [g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+\Omega(f_t)\) (\(g_i 为一阶导数 h_i 为二阶导数)\)
-
用函数来描述树结构: 用叶子节点的值以及叶子节点的编号来表示第t棵树的预测值,模型复杂度用节点数量以及叶子节点值的平方来描述 最终的目标函数为 \(Obj = -\frac{1}{2}\sum_{j=1}^T \frac{G_j^2}{H_j+\lambda} + \gamma T\)
-
贪心算法建树: 前面的步骤是基于树结构为已知的前提推导得出, 所以贪心的尝试对不同特征进行分割, 用上面的函数对每一种分割打分,(类似于计算gini系数构建决策树的方式)找到增益分数最大的分割方式
- 缺失值处理: 在训练过程中,如果特征\(f_0\)出现了缺失值,会为该特征计算一个缺失值划分方向(左子树,右子树)
2. XGBoost API¶
2.1 通用参数¶
booster [缺省值=gbtree]
- gbtree:使用树模型
- gblinear:使用线性模型
- dart:使用树模型,主要多了 Dropout
silent [缺省值=0]
- 设置为 0 打印运行信息
- 设置为 1不打印运行信息
nthread [缺省值=设置为最大可能的线程数]
- 并行运行的线程数,输入的参数应该 <= 系统的CPU核心数
- 若是没有设置算法会检测将其设置为 CPU 的全部核心数
下面的两个参数不需要设置,使用默认的就好了
num_pbuffer [xgboost自动设置,不需要用户设置]
- 预测结果缓存大小,通常设置为训练实例的个数。该缓存用于保存最后 boosting 操作的预测结果
num_feature [xgboost自动设置,不需要用户设置]
- 在boosting中使用特征的维度,设置为特征的最大维度
2.2 Booster 参数¶
2.2.1 Parameters for Tree Booster¶
eta [缺省值=0.3,别名:learning_rate]
- 更新中减少的步长来防止过拟合
- 每次 boosting 之后,可以直接获得新的特征权值,这样可以使得 boosting 更加鲁棒
- 范围: [0,1]
gamma [缺省值=0,别名: min_split_loss](分裂最小loss)
- gamma 指定了节点分裂所需的最小损失函数下降值
- 这个参数的值和损失函数息息相关,所以是需要调整的
- 范围: [0, ∞]
max_depth [缺省值=6]
- 这个值为树的最大深度。 这个值也是用来避免过拟合的
- max_depth越大,模型会学到更具体更局部的样本
- 设置为 0 代表没有限制
- 范围: [0 ,∞]
min_child_weight [缺省值=1]
- 当它的值较大时,可以避免模型学习到局部的特殊样本
- 如果这个值过高,会导致欠拟合
- 范围: [0,∞]
subsample [缺省值=1]
- 这个参数控制对于每棵树,随机采样的比例
- 如果这个值设置得过大,它可能会导致过拟合
- 如果这个值设置得过小,它可能会导致欠拟合
- 典型值:0.5-1,0.5 代表平均采样,防止过拟合
- 范围: (0,1]
colsample_bytree [缺省值=1]
- 控制每棵随机特征采样的比例
- 范围: (0,1],典型值:0.5-1
colsample_bylevel [缺省值=1]
- 用来控制树每一次分裂时对特征的采样的比例
- 范围: (0,1]
alpha [缺省值=0,别名: reg_alpha]
- 权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快
scale_pos_weight[缺省值=1]
- 在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛
- 通常可以将其设置为负样本的数目与正样本数目的比值
2.2.2 Parameters for Linear Booster¶
linear booster一般很少用到。
lambda [缺省值=0,别称: reg_lambda]
- L2 正则化惩罚系数,增加该值会使得模型更加保守
alpha [缺省值=0,别称: reg_alpha]
- L1正则化惩罚系数,增加该值会使得模型更加保守。
lambda_bias [缺省值=0,别称: reg_lambda_bias]
- 偏置上的 L2 正则化(没有在L1上加偏置,因为并不重要)
2.3 学习目标参数¶
objective [缺省值=reg:linear]
- reg:linear:线性回归
- reg:logistic: 逻辑回归
- binary:logistic:二分类逻辑回归,输出为概率
- multi:softmax:使用softmax的多分类器,返回预测的类别(不是概率)。在这种情况下,你还需要多设一个参数:num_class(类别数目)
- multi:softprob:和multi:softmax参数一样,但是返回的是每个数据属于各个类别的概率。
eval_metric [缺省值=通过目标函数选择] 验证集
可供选择的如下所示:
- rmse: 均方根误差
- mae: 平均绝对值误差
- logloss: 负对数似然函数值
- error:其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。
- error@t: 不同的划分阈值可以通过 ‘t’进行设置
- merror: 多分类错误率,计算公式为(wrong cases)/(all cases)
- mlogloss: 多分类log损失
- auc: 曲线下的面积
seed [缺省值=0]
- 随机数的种子,设置它可以复现随机数据的结果,也可以用于调整参数
3. 小结¶
- XGBoost 算法是对 GBDT 的改进,在损失函数中增加了正则化项,综合考虑了模型的结构风险
- XGBoost 使用自己的分裂增益计算方法来构建强学习器