损失函数和正规方程¶
学习目标¶
- 掌握损失函数的概念与作用
- 了解正规方程
- 掌握正规方程的使用
1. 损失函数的概念¶
损失函数的概念:
- 用来衡量机器学习模型性能的函数
- 损失函数可以计算预测值与真实值之间的误差(用一个实数来表示),误差越小说明模型性能越好
损失函数的作用:
- 确定损失函数之后, 我们通过求解损失函数的极小值来确定机器学习模型中的参数
先看下面的例子,有如下一组训练数据:
X = [0.0, 1.0, 2.0, 3.0]
y = [0.0, 2.5, 3.3, 6.2]
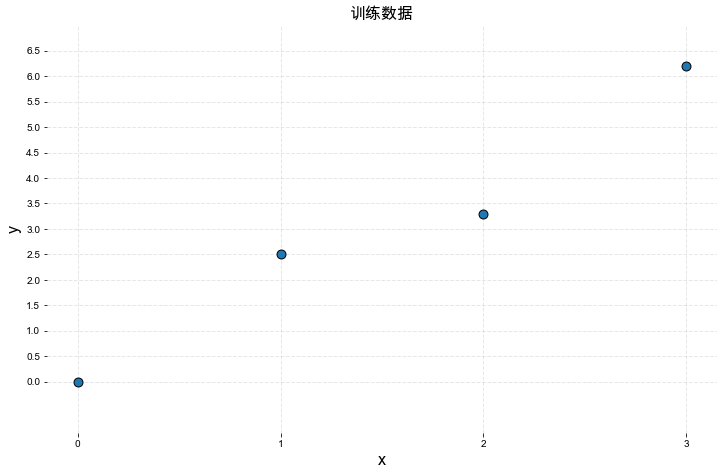
很显然,上面的数据中,X与y的关系可以近似的表示为一元线性关系, 即 y = WX
注意:当前例子中, y 和 X均为已知,由训练数据给出,W为未知
训练线性回归模型模型的过程实际上就是要找到一个 合适的W ,那么什么才是合适的W,我们先随机的给出几个W看下效果
当W = 5.0时如下图所示:
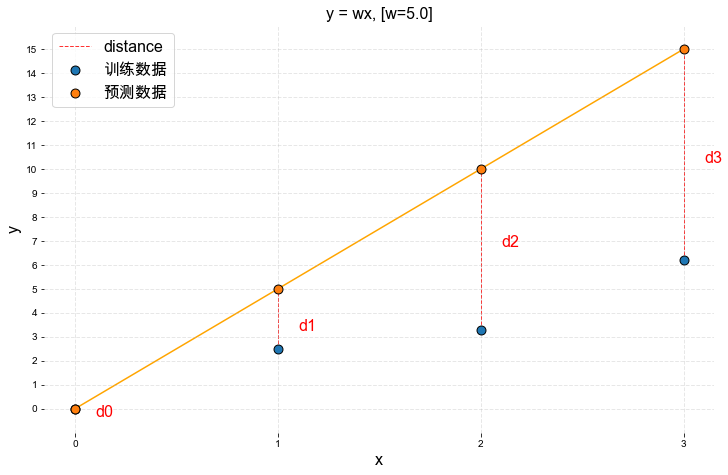
从上图中可以观察到模型预测值与真实值不同,我们希望通过一个数学表达式来表示这个差值:
- 很自然的能想到,将真实值与预测值相减并查看结果是否等于零,不为零意味着预测有误差
- 误差的大小是坐标系中两点之间的距离
我们将距离定义为: \(distance = \hat{y}-y\)
根据上面的公式, 我们可以计算出当W=5.0时预测的误差分别为:
\(d_0 = 0-0 = 0\)
\(d_1 = 5-2.5 = 2.5\)
\(d_2 = 10-3.3 = 6.7\)
\(d_3 = 15-6.2 = 8.8\)
在前面的概念中提到, 损失函数的计算结果应该为一个具体的实数,因此我们将上面所有点的预测误差相加得到:
\(cost(w)=d_0+d_1+d_2+d_3\)
\(cost(5) = 0+2.5+6.7+8.8 = 18\)
从上面的结果中发现,误差有些大,我们的模型应该还有调整的空间,尝试将W减小,令W=0.5
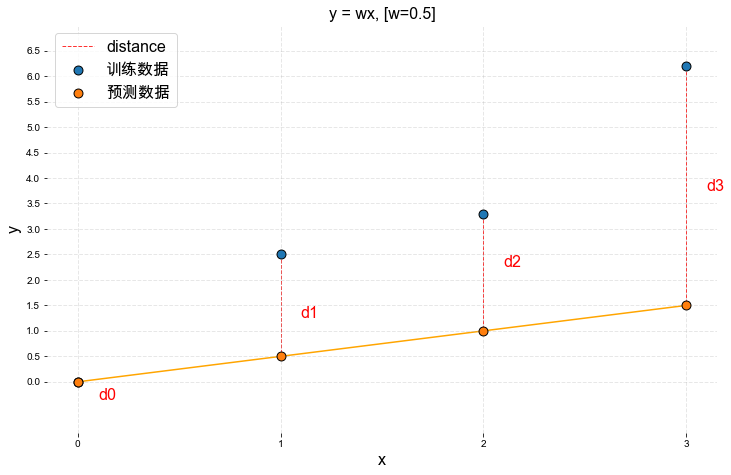
根据公式 \(distance = \hat{y}-y\), 我们可以计算出当W=0.5时预测的误差分别为:
\(d_0 = 0-0 = 0\)
\(d_1 = 0.5-2.5 = -2\)
\(d_2 = 1-3.3 = -2.3\)
\(d_3 = 1.5-6.2 = -4.7\)
\(cost(w)=d_0+d_1+d_2+d_3\)
\(cost(0.5) = 0-2-2.5-4.7 = -9\)
再尝试W=2:
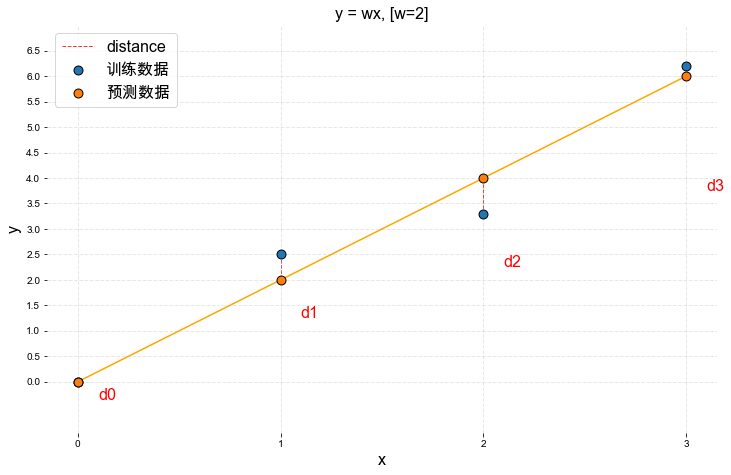
根据公式 \(distance = \hat{y}-y\), 我们可以计算出当W=2时预测的误差分别为:
\(d_0 = 0-0 = 0\)
\(d_1 = 2-2.5 = -0.5\)
\(d_2 = 4-3.3 = 0.7\)
\(d_3 = 6-6.2 = -0.2\)
\(cost(w)=d_0+d_1+d_2+d_3\)
\(cost(2) = 0-0.5+0.7-0.2 = 0\)
我们前面提到,利用损失函数可以确定损失的大小,损失越小的模型效果越好,通过对比发现
\(cost(5) = 0+2.5+6.7+8.8 = 18\)
\(cost(0.5) = 0-2-2.5-4.7 = -9\)
\(cost(2) = 0-0.5+0.7-0.2 = 0\)
当前的计算方法中
- 当W=0.5的cost的值最小,但从图像中可以看出当W=2时,模型拟合的更好
- 当W=2时计算出的误差为0,但实际情况除了d0之外其余点均存在预测误差
综上所述,我们用来衡量回归损失的时候, 不能简单的将每个点的预测误差相加
2. 平方损失¶
回归问题的损失函数通常用下面的函数表示:
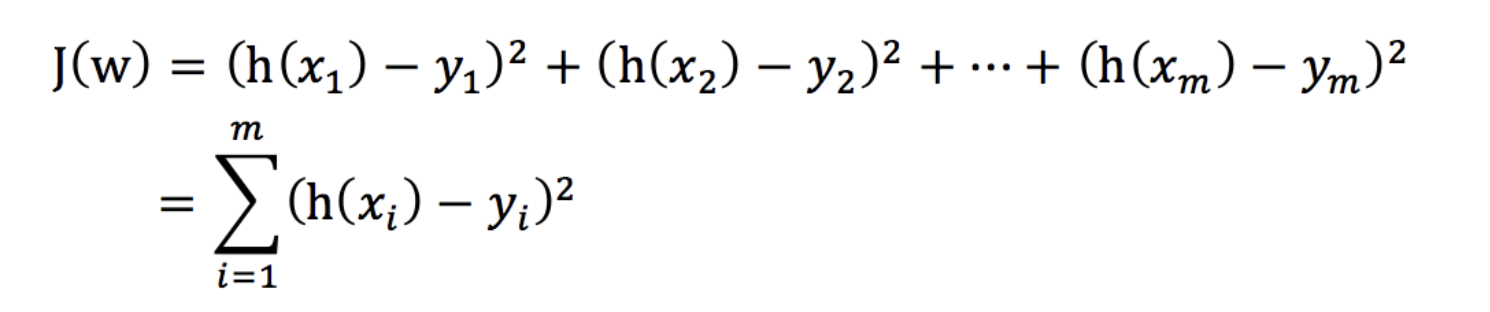
- yi 为第i个训练样本的真实值
- h(xi) 为第i个训练样本特征值组合预测函数又称最小二乘法
我们的目标是: 找到该损失函数最小时对应的 w、b.
- 接下来我们开始对平方损失求解最优解
3. 正规方程¶
正规方程公式: \(\huge W=(X^TX)^{-1}X^TY\)
那么,该公式是如何得出的?
\(\large J(w) = \sum_{i=1}^n (w^Tx_i-y_i)^2\)
\(=(w^Tx_1-y_1,w^Tx_2-y_2,\cdots ,w^Tx_n-y_n)\cdot\left( \begin{matrix}w^Tx_1-y_1 \\ w^Tx_2-y_2 \\ \cdots \\w^Tx_n-y_n \end{matrix} \quad \right)\)
上面式子中左边的部分 \((w^Tx_1-y_1,w^Tx_2-y_2,\cdots ,w^Tx_n-y_n)\) = \((w^Tx_1,w^Tx_2,\cdots ,w^Tx_n)-(y_1,y_2,\cdots,y_n)\)
=\(w^T(x_1,x_2,\cdots,x_n)-(y_1,y_2,\cdots,y_n)\)
= \(W^TX^T-Y^T\)
右边部分等于左边部分的转置 = \(XW-Y\) 所以
\(\large J(w) = \sum_{i=1}^n (w^Tx_i-y_i)^2=(W^TX^T-Y^T)(XW-Y)\)
\(\large =W^TX^TXW-W^TX^TY-Y^TXW+Y^TY\)
\(\large =W^TX^TXW-2W^TX^TY+Y^TY\)
上式对W求导数
\(\large \frac{∂J}{∂W} = 2X^TXW-2X^TY\)
令导数等于0 可以求得W
\(\large 2X^TXW-2X^TY=0\)
\(\large X^TXW=X^TY\)
\(\large W=(X^TX)^{-1}X^TY\)
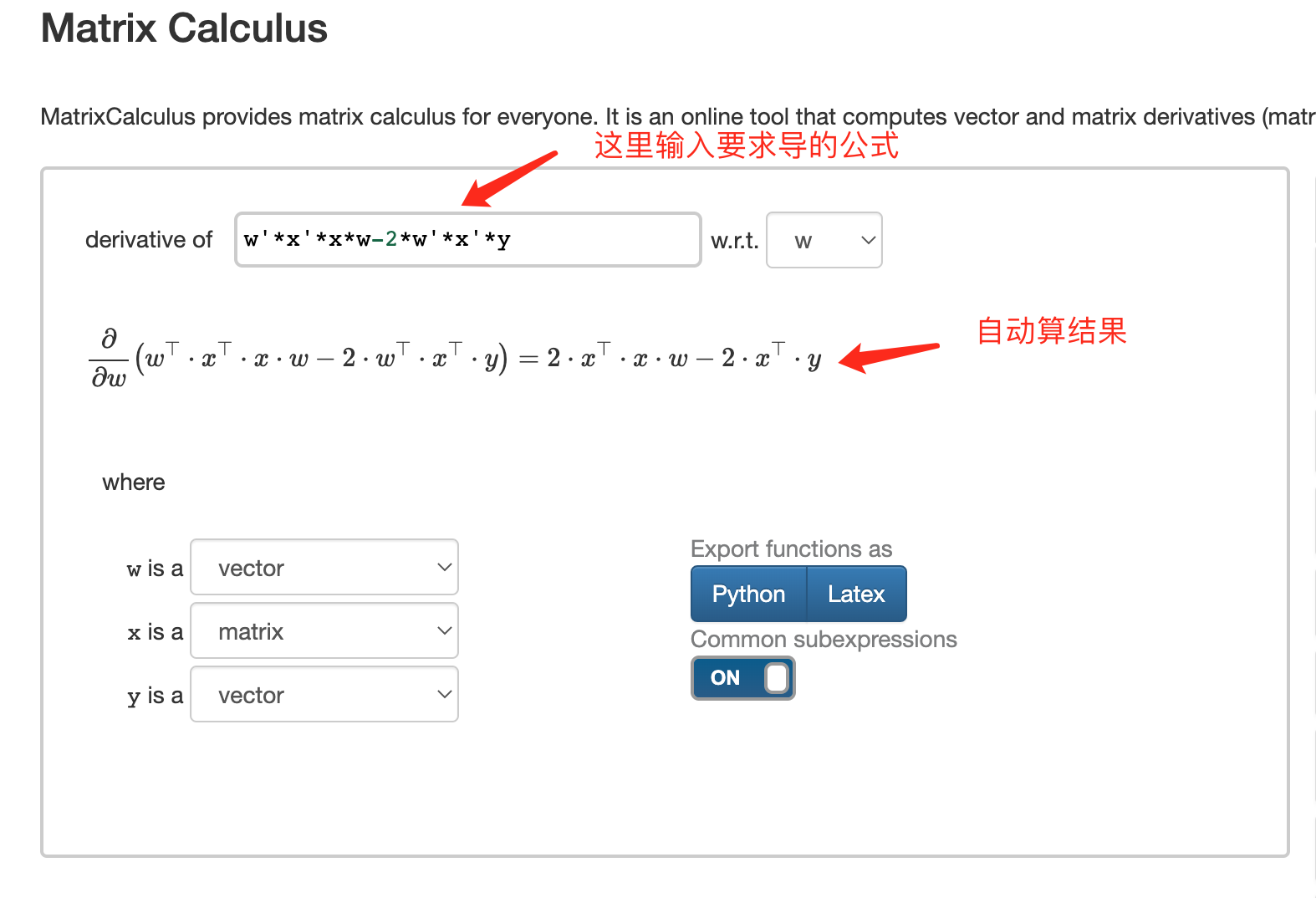
如对矩阵求导不熟悉可以使用http://www.matrixcalculus.org/ 辅助计算
示例代码:
import numpy as np
from sklearn.linear_model import LinearRegression
if __name__ == '__main__':
# 特征值
x = np.mat([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
# 目标值
y = np.mat([84.2, 80.6, 80.1, 90, 83.2, 87.6, 79.4, 93.4]).transpose()
# 给特征值增加一列1
ones_array = np.ones([len(x), 1])
x = np.hstack([ones_array, x])
# 使用正规方程公式计算 w、b
w = (x.transpose() * x) ** -1 * x.transpose() * y
print('[%.1f %.1f %.1f]' % (w[0][0], w[1][0], w[2][0]))
# 使用 LinearRegression 求解
estimator = LinearRegression(fit_intercept=True)
estimator.fit(x, y)
print(estimator.coef_[0])
# 输出结果
# [0.0 0.3 0.7]
# [0. 0.3 0.7]
4. 小结¶
- 损失函数在训练阶段能够指导模型的优化方向,在测试阶段能够用于评估模型的优劣。
- 线性回归使用平方损失
- 正规方程是线性回归的一种优化方法